Data Warehouse vs Data Mart vs Data Lake
I termini data lake e data warehouse sono spesso confusi e talvolta usati in modo intercambiabile. In realtà, anche se entrambi servono a memorizzare enormi set di dati, data lake e data warehouse sono diversi (e possono essere complementari).
- Data Lake - è un enorme insieme di dati che può contenere qualsiasi tipo di dato: strutturato, semi-strutturato o non strutturato.
- Data warehouse - è un repository per dati strutturati e filtrati che sono già stati elaborati per uno scopo specifico. In altre parole, un data warehouse è ben organizzato e contiene dati ben definiti.
- Data mart - è un sottoinsieme di un data warehouse, utilizzato da una specifica unità aziendale per uno scopo preciso, come un'applicazione di gestione della supply chain.
James Dixon, ideatore del termine data lake, spiega le differenze con un'analogia: “Se pensi a un data mart come a una riserva di acqua in bottiglia — depurata, confezionata e strutturata per un facile consumo — il data lake è un grande corpo d'acqua in uno stato più naturale. Il contenuto del data lake arriva da una fonte per riempirlo, e i vari utenti del lake possono venire a esaminarlo, immergersi o prelevare campioni.”
Un data lake può essere usato insieme a un data warehouse. Ad esempio, puoi usare un data lake come repository di landing e staging per un data warehouse. Puoi usare il data lake per curare o ripulire i dati prima di riversarli in un data warehouse o in altre strutture dati.
I data lake che non vengono curati corrono il rischio di trasformarsi in data swamp, senza governance né decisioni di qualità applicate ai dati, riducendo drasticamente il valore della raccolta dei dati “mescolando” dati di qualità diversa in un modo che rende difficile fare affidamento sulla validità delle decisioni prese a partire dai dati raccolti.
Il seguente diagramma rappresenta un tipico stack tecnologico di un data lake. Il data lake include risorse scalabili di archiviazione e calcolo; strumenti di elaborazione dei dati per la gestione dei dati; strumenti di analisi e reporting per data scientist, utenti aziendali e personale tecnico; e sistemi comuni di governance dei dati, sicurezza e operazioni.
Puoi implementare un data lake in un data center aziendale o nel cloud. Molti early adopter hanno distribuito data lake on-premises. Con la maggiore diffusione dei data lake, molti adottanti mainstream stanno guardando ai data lake basati sul cloud per accelerare il time-to-value, ridurre il TCO e migliorare l'agilità aziendale.
I data lake on-premises sono intensivi in CAPEX e OPEX
Puoi implementare un data lake in un data center aziendale utilizzando server commodity e archiviazione locale (interna). Oggi la maggior parte dei data lake on-premises utilizza una versione commerciale o open source di Hadoop, un noto framework di calcolo ad alte prestazioni, come piattaforma dati. (Nel sondaggio TDWI, il 53% degli intervistati utilizza Hadoop come piattaforma dati, mentre solo il 6% utilizza un sistema di gestione di database relazionali.)
Puoi combinare centinaia o migliaia di server per creare un cluster Hadoop scalabile e resiliente, capace di memorizzare ed elaborare enormi set di dati. Il diagramma seguente mostra uno stack tecnologico per un data lake on-premises basato su Apache Hadoop.
Lo stack tecnologico include:
-
Hadoop MapReduce:
Un framework software per scrivere facilmente applicazioni che elaborano enormi quantità di dati in parallelo su grandi cluster di hardware commodity in modo affidabile e tollerante ai guasti.
-
Hadoop YARN:
Un framework per la pianificazione dei job e la gestione delle risorse del cluster.
-
Hadoop Distributed File System (HDFS):
Un file system ad alte prestazioni progettato specificamente per funzionare su server a basso costo, con dischi interni economici.
I data lake on-premises offrono prestazioni elevate e forte sicurezza, ma sono notoriamente costosi e complessi da distribuire, amministrare, mantenere e scalare. Gli svantaggi di un data lake on-premises includono:
Installazione lunga e complessa
Costruire un proprio data lake richiede tempo, impegno e denaro significativi. Bisogna progettare e definire l'architettura del sistema; stabilire e introdurre sistemi di sicurezza e amministrazione e le best practice; procurare, mettere in opera e testare l'infrastruttura di calcolo, archiviazione e rete; e identificare, installare e configurare tutti i componenti software. Di solito servono mesi (spesso oltre un anno) per portare un data lake on-premises in produzione.
CAPEX elevato
Consistenti spese iniziali per le apparecchiature portano a modelli di business sbilanciati, con ROI bassi e lunghi tempi di rientro. Server, dischi e infrastruttura di rete sono tutti sovradimensionati per soddisfare i picchi di traffico e i futuri requisiti di capacità, quindi si paga sempre per risorse di calcolo inattive e capacità di archiviazione e rete inutilizzata.
OPEX elevato
Spese ricorrenti per energia, raffreddamento e spazio rack; canoni mensili di manutenzione hardware e supporto software; e costi continui di amministrazione dell'hardware portano a elevate spese operative delle apparecchiature.
Rischio elevato
Garantire la continuità operativa (replicando i dati live in un data center secondario) è una proposta costosa, fuori dalla portata della maggior parte delle aziende. Molte aziende eseguono il backup dei dati su nastro o su disco. In caso di catastrofe possono servire giorni o persino settimane per ricostruire i sistemi e ripristinare le operazioni.
Amministrazione di sistema complessa
Gestire un data lake on-premises richiede molte risorse e sottrae personale IT prezioso (e costoso) ad attività più strategiche.
I data lake cloud eliminano costi e complessità delle apparecchiature
Puoi implementare un data lake in un cloud pubblico per evitare spese e complicazioni legate alle apparecchiature e accelerare le iniziative big data. I vantaggi generali di un data lake basato sul cloud includono:
Time-to-value rapido
Puoi ridurre i tempi di distribuzione da mesi a settimane eliminando le attività di progettazione dell'infrastruttura e di approvvigionamento, installazione e avvio dell'hardware.
Nessun CAPEX
Puoi evitare gli esborsi iniziali di capitale, allineare meglio le spese ai requisiti aziendali e liberare budget di capitale per altri programmi.
Nessuna spesa operativa per le apparecchiature
Puoi eliminare le spese operative ricorrenti per le apparecchiature (energia, raffreddamento, spazi immobiliari), i canoni annuali di manutenzione hardware e i costi ricorrenti di amministrazione del sistema.
Scalabilità istantanea e infinita
Puoi aggiungere capacità di calcolo e archiviazione on-demand per soddisfare requisiti aziendali in rapida evoluzione e migliorare la soddisfazione dei clienti (rispondendo rapidamente alle esigenze delle linee di business).
Scalabilità indipendente
A differenza di un'implementazione Hadoop on-premises che si basa su server con archiviazione interna, con un'implementazione cloud puoi scalare indipendentemente capacità di calcolo e archiviazione per ottimizzare i costi e sfruttare al massimo le risorse.
Rischio minore
Puoi replicare i dati tra regioni per migliorare la resilienza e garantire disponibilità continua in caso di catastrofe.
Operazioni semplificate
Puoi liberare il personale IT affinché si concentri su attività strategiche a supporto del business (il provider cloud gestisce l'infrastruttura fisica).
I servizi di cloud storage di prima generazione sono troppo costosi e complessi per i data lake
Rispetto a un data lake on-premises, un data lake basato sul cloud è molto più semplice e meno costoso da distribuire, scalare e gestire. Detto questo, i servizi di object storage cloud di prima generazione come AWS S3, Microsoft Azure Blob Storage e Google Cloud Platform Storage sono intrinsecamente costosi (in molti casi quasi quanto le soluzioni di archiviazione on-premises) e complicati. Molte aziende cercano servizi di archiviazione più semplici e più convenienti per le iniziative data lake. I limiti dei servizi di object storage cloud di prima generazione includono:
Livelli di servizio costosi e confusi
I fornitori cloud tradizionali vendono diversi tipi (livelli) di servizi di archiviazione. Ogni livello è pensato per uno scopo distinto, ad esempio archiviazione primaria per dati attivi, archiviazione di archivio attivo per il disaster recovery o archiviazione di archivio inattivo per la conservazione dei dati a lungo termine. Ognuno ha caratteristiche uniche di prestazioni e resilienza, SLA e piani tariffari. Strutture tariffarie complesse con molte variabili rendono difficile fare scelte consapevoli, prevedere i costi e gestire i budget.
Lock-in del fornitore
Ogni provider di servizi supporta una API unica. Cambiare servizio è una proposta costosa e dispendiosa in termini di tempo: devi riscrivere o sostituire i tuoi strumenti e le tue applicazioni esistenti per la gestione dell'archiviazione. Peggio ancora, i fornitori tradizionali applicano costi eccessivi di trasferimento dati (egress) per spostare i dati fuori dal loro cloud, rendendo costoso cambiare provider o usare una combinazione di provider.
Attenzione ai servizi di archiviazione a livelli
I provider cloud di prima generazione offrono servizi di archiviazione a livelli confusi. Ogni livello di archiviazione è pensato per uno specifico tipo di dato e ha caratteristiche di prestazioni, SLA e piani tariffari distinti (con strutture di costo complesse).
Anche se il portafoglio di ogni fornitore è leggermente diverso, questi servizi a livelli sono generalmente ottimizzati per tre classi distinte di dati.
Dati attivi
Dati live facilmente accessibili dal sistema operativo, da un'applicazione o dagli utenti. I dati attivi vengono consultati frequentemente e richiedono prestazioni di lettura/scrittura rigorose.
Archivio attivo
Dati accessi occasionalmente, disponibili immediatamente online (non ripristinati o reidratati da una fonte offline o remota). Esempi includono dati di backup per un rapido disaster recovery o grandi file video che potrebbero essere accessi di tanto in tanto con breve preavviso.
Archivio inattivo
Dati accessi raramente. Esempi includono dati conservati a lungo termine per la conformità normativa. Storicamente, i dati inattivi vengono archiviati su nastro e conservati fuori sede.
Individuare la classe di archiviazione migliore (e il miglior rapporto qualità-prezzo) per una determinata applicazione può essere una vera sfida con un provider cloud tradizionale. Microsoft Azure, ad esempio, offre quattro diverse opzioni di object storage: General Purpose v1, General Purpose v2, Blob Storage e Premium Blob Storage. Ogni opzione ha caratteristiche uniche di prezzo e prestazioni. E alcune (ma non tutte) le opzioni supportano tre distinti livelli di archiviazione, con SLA e costi diversi: archiviazione hot (per dati frequentemente accessi), archiviazione cool (per dati accessi di rado) e archiviazione archive (per dati accessi raramente). Con così tante scelte e variabili di prezzo, è quasi impossibile prendere una decisione ben informata e pianificare con precisione le spese.
In IDrive® e2 crediamo che l'archiviazione cloud debba essere semplice. A differenza dei servizi cloud tradizionali con livelli di archiviazione confusi e schemi di prezzo contorti, offriamo un unico prodotto — con prezzi prevedibili, convenienti e trasparenti — che soddisfa qualsiasi esigenza di archiviazione cloud. Puoi usare IDrive® e2 per qualsiasi classe di archiviazione dati: dati attivi, archivio attivo e archivio inattivo.
IDrive® e2 Hot Cloud Storage per Data Lake
L'archiviazione cloud hot di IDrive® e2 è un object storage cloud estremamente economico, veloce e affidabile per qualsiasi scopo. A differenza dei servizi cloud di prima generazione con livelli di archiviazione confusi e schemi tariffari complessi, IDrive® e2 è facile da comprendere ed estremamente conveniente da scalare. IDrive® e2 è ideale per archiviare enormi volumi di dati grezzi.
I principali vantaggi di IDrive® e2 per i data lake includono:
Prezzi competitivi
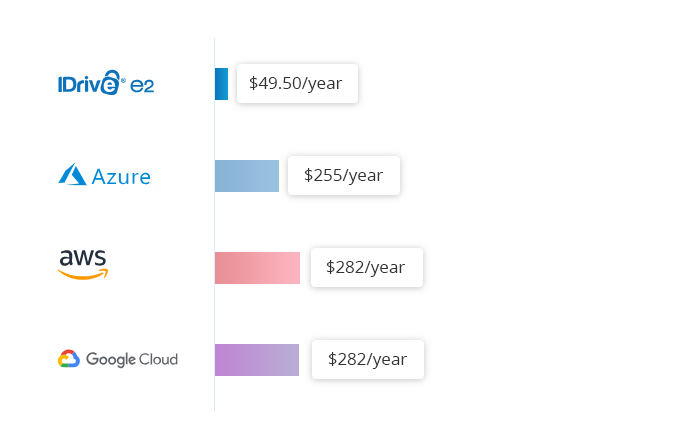
L'archiviazione cloud hot di IDrive® e2 costa una tariffa fissa di $0.004/GB/mese. Confrontala con $.023/GB/mese per Amazon S3 Standard, $.026/GB/mese per Google Multi-Regional e $.046/GB/mese per Azure RA-GRS Hot.
A differenza di AWS, Microsoft Azure e Google Cloud Platform, non applichiamo costi aggiuntivi per il recupero dei dati dall'archiviazione (costi di egress). Inoltre non addebitiamo costi extra per le chiamate API.
Prestazioni superiori
L'architettura di sistema parallelizzata di IDrive® e2 offre prestazioni di lettura/scrittura più rapide rispetto ai servizi cloud di prima generazione, con tempi di time-to-first-byte significativamente più veloci.
Durabilità e protezione dei dati robuste
L'archiviazione cloud hot di IDrive® e2 è progettata per offrire estrema durabilità, integrità e sicurezza dei dati. Una funzione opzionale di immutabilità dei dati impedisce cancellazioni accidentali e errori amministrativi; protegge da malware, bug e virus; e migliora la conformità normativa.
IDrive® e2 Hot Cloud Storage per Data Lake Apache Hadoop
Se esegui il tuo data lake su Apache Hadoop, puoi usare l'archiviazione cloud hot di IDrive® e2 come alternativa conveniente a HDFS, come mostrato nel diagramma seguente. L'archiviazione cloud hot di IDrive® e2 è pienamente compatibile con l'API AWS S3. Puoi usare il connettore Hadoop Amazon S3A, parte della distribuzione open source Apache Hadoop, per integrare Amazon S3 e altri cloud storage compatibili come IDrive® e2 in vari flussi MapReduce.
Puoi usare l'archiviazione cloud hot di IDrive® e2 come parte di un'implementazione multi-cloud di data lake per aumentare la scelta ed evitare il lock-in del fornitore. Un approccio multi-cloud consente di scalare indipendentemente le risorse di calcolo e archiviazione del data lake, usando i migliori provider disponibili.
Puoi anche collegare direttamente il tuo cloud privato a IDrive® e2. A differenza dei provider cloud di prima generazione, con IDrive® e2 non paghi mai costi di trasferimento dati (egress). In altre parole, puoi spostare liberamente i dati fuori da IDrive® e2.
Continuità operativa e disaster recovery convenienti
IDrive® e2 è ospitato in più data center geograficamente distribuiti per garantire resilienza e alta disponibilità. Puoi replicare i dati tra le regioni di IDrive® e2 per continuità operativa, disaster recovery e protezione dei dati, come mostrato di seguito.
Ad esempio, potresti replicare i dati su tre diversi data center (regioni) di IDrive® e2 utilizzando:
- IDrive® e2 Data Center 1 per l'archiviazione dei dati attivi (archiviazione primaria).
- IDrive® e2 Data Center 2 come archivio attivo per backup e ripristino (standby caldo nel caso in cui il Data Center 1 non sia raggiungibile).
- IDrive® e2 Data Center 3 come archivio dati immutabile (per proteggere i dati da errori amministrativi, cancellazioni accidentali e ransomware). Un oggetto dati immutabile non può essere eliminato o modificato da nessuno, incluso IDrive® e2.