Entrepôt de données vs Data Mart vs Lac de données
Les termes lac de données et entrepôt de données sont souvent confondus et parfois utilisés de manière interchangeable. En réalité, bien que les deux servent à stocker des jeux de données massifs, les lacs de données et les entrepôts de données sont différents (et peuvent être complémentaires).
- Lac de données - est un vaste réservoir de données pouvant contenir tout type de données — structurées, semi-structurées ou non structurées.
- Entrepôt de données - est un référentiel de données structurées et filtrées, déjà traitées dans un but précis. En d’autres termes, un entrepôt de données est bien organisé et contient des données bien définies.
- Data mart - est un sous-ensemble d’un entrepôt de données, utilisé par une unité métier spécifique de l’entreprise pour un objectif précis, comme une application de gestion de la chaîne d’approvisionnement.
James Dixon, à l’origine du terme « data lake », explique les différences à l’aide d’une analogie : « Si vous considérez un data mart comme un magasin d’eau en bouteille — purifiée, conditionnée et structurée pour une consommation facile — alors le lac de données est une vaste étendue d’eau dans un état plus naturel. Le contenu du lac de données arrive d’une source pour remplir le lac, et différents utilisateurs peuvent venir l’examiner, y plonger ou en prélever des échantillons. »
Un lac de données peut être utilisé conjointement avec un entrepôt de données. Par exemple, vous pouvez utiliser un lac de données comme référentiel d’atterrissage et de préparation pour un entrepôt de données. Vous pouvez utiliser le lac de données pour organiser ou nettoyer les données avant de les alimenter dans un entrepôt de données ou d’autres structures de données.
Les lacs de données qui ne sont pas organisés risquent de devenir des marécages de données, sans gouvernance ni décisions de qualité appliquées aux données, ce qui réduit fortement la valeur de la collecte des données en « brouillant » des données de qualité hétérogène d’une manière qui rend difficile de se fier à la validité des décisions prises à partir des données collectées.
Le schéma suivant représente une pile technologique typique de lac de données. Le lac de données comprend des ressources de stockage et de calcul évolutives ; des outils de traitement des données pour la gestion des données ; des outils d’analyse et de reporting pour les data scientists, les utilisateurs métier et les équipes techniques ; ainsi que des systèmes communs de gouvernance des données, de sécurité et d’exploitation.
Vous pouvez implémenter un lac de données dans un centre de données d’entreprise ou dans le cloud. De nombreux premiers adopteurs ont déployé des lacs de données sur site. À mesure que les lacs de données se généralisent, de nombreux adopteurs traditionnels se tournent vers des lacs de données basés sur le cloud pour accélérer la mise en valeur, réduire le TCO et améliorer l’agilité métier.
Les lacs de données sur site sont intensifs en CAPEX et OPEX
Vous pouvez implémenter un lac de données dans un centre de données d’entreprise en utilisant des serveurs standards et un stockage local (interne). Aujourd’hui, la plupart des lacs de données sur site utilisent une version commerciale ou open source de Hadoop, un framework populaire de calcul haute performance, comme plateforme de données. (Dans l’enquête TDWI, 53 % des répondants utilisent Hadoop comme plateforme de données, tandis que seulement 6 % utilisent un système de gestion de base de données relationnelle.)
Vous pouvez combiner des centaines ou des milliers de serveurs pour créer un cluster Hadoop évolutif et résilient, capable de stocker et de traiter des jeux de données massifs. Le schéma ci-dessous illustre une pile technologique pour un lac de données sur site basé sur Apache Hadoop.
The technology stack includes:
-
Hadoop MapReduce:
Un cadre logiciel permettant d’écrire facilement des applications qui traitent de très grands volumes de données en parallèle sur de vastes clusters de matériel standard, de manière fiable et tolérante aux pannes.
-
Hadoop YARN:
Un framework pour l’ordonnancement des tâches et la gestion des ressources du cluster.
-
Hadoop Distributed File System (HDFS):
Un système de fichiers haute performance spécialement conçu pour fonctionner sur des serveurs à faible coût, avec des disques internes économiques.
Les lacs de données sur site offrent de hautes performances et une sécurité renforcée, mais ils sont réputés coûteux et complexes à déployer, administrer, maintenir et faire évoluer. Les inconvénients d’un lac de données sur site incluent :
Installation longue et laborieuse
Construire votre propre lac de données demande beaucoup de temps, d’efforts et d’argent. Vous devez concevoir et architecturer le système ; définir et mettre en place des systèmes de sécurité et d’administration ainsi que des bonnes pratiques ; approvisionner, installer et tester l’infrastructure de calcul, de stockage et de réseau ; puis identifier, installer et configurer tous les composants logiciels. Il faut généralement des mois (souvent plus d’un an) pour mettre en production un lac de données sur site.
CAPEX élevé
D’importants investissements matériels initiaux conduisent à des modèles économiques déséquilibrés, avec un faible ROI et des délais de rentabilité longs. Les serveurs, les disques et l’infrastructure réseau sont souvent surdimensionnés pour répondre aux pics de trafic et aux besoins futurs de capacité ; vous payez donc en permanence pour des ressources de calcul inactives et des capacités de stockage et de réseau inutilisées.
OPEX élevé
Les dépenses récurrentes d’électricité, de refroidissement et d’espace en baie ; les frais mensuels de maintenance matérielle et de support logiciel ; ainsi que les coûts continus d’administration du matériel entraînent des coûts d’exploitation élevés.
Risque élevé
Assurer la continuité d’activité (répliquer les données en production vers un centre de données secondaire) est une démarche coûteuse hors de portée de nombreuses entreprises. Beaucoup d’entreprises sauvegardent les données sur bande ou sur disque. En cas de catastrophe, il peut falloir plusieurs jours, voire plusieurs semaines, pour reconstruire les systèmes et rétablir les opérations.
Administration système complexe
L’exploitation d’un lac de données sur site mobilise fortement les ressources et détourne un personnel IT précieux (et coûteux) d’initiatives plus stratégiques.
Les lacs de données cloud éliminent les coûts et la complexité des équipements
Vous pouvez implémenter un lac de données dans un cloud public pour éviter les dépenses et contraintes matérielles et accélérer les initiatives big data. Les avantages généraux d’un lac de données basé sur le cloud incluent :
Mise en valeur rapide
Vous pouvez réduire les délais de déploiement de plusieurs mois à quelques semaines en éliminant les efforts de conception d’infrastructure ainsi que les tâches d’approvisionnement, d’installation et de mise en service du matériel.
Pas de CAPEX
Vous pouvez éviter les investissements initiaux, mieux aligner les dépenses sur les besoins métiers et libérer du budget d’investissement pour d’autres programmes.
Pas de dépenses d’exploitation des équipements
Vous pouvez éliminer les coûts d’exploitation continus des équipements (électricité, refroidissement, immobilier), les frais annuels de maintenance matérielle et les coûts récurrents d’administration système.
Évolutivité instantanée et infinie
Vous pouvez ajouter à la demande des capacités de calcul et de stockage pour répondre à l’évolution rapide des besoins métiers et améliorer la satisfaction client (répondre rapidement aux exigences des lignes métier).
Mise à l’échelle indépendante
Contrairement à une implémentation Hadoop sur site qui repose sur des serveurs avec stockage interne, une implémentation cloud vous permet de faire évoluer indépendamment les capacités de calcul et de stockage afin d’optimiser les coûts et d’utiliser au mieux les ressources.
Risque réduit
Vous pouvez répliquer les données entre plusieurs régions pour améliorer la résilience et garantir une disponibilité continue en cas de catastrophe.
Opérations simplifiées
Vous pouvez libérer les équipes IT pour qu’elles se concentrent sur des tâches stratégiques au service de l’entreprise (le fournisseur cloud gère l’infrastructure physique).
Les services cloud de stockage de première génération sont trop coûteux et complexes pour les lacs de données
Comparé à un lac de données sur site, un lac de données basé sur le cloud est bien plus simple et moins coûteux à déployer, faire évoluer et exploiter. Cela dit, les services de stockage objet cloud de première génération comme AWS S3, Microsoft Azure Blob Storage et Google Cloud Platform Storage sont intrinsèquement coûteux (dans de nombreux cas, aussi chers que des solutions de stockage sur site) et complexes. De nombreuses entreprises recherchent des services de stockage plus simples et plus abordables pour leurs initiatives de lac de données. Les limites des services de stockage objet cloud de première génération incluent :
Niveaux de service coûteux et déroutants
Les fournisseurs cloud historiques vendent plusieurs types (niveaux) de services de stockage. Chaque niveau est destiné à un usage distinct, par exemple : stockage primaire pour les données actives, stockage d’archive active pour la reprise après sinistre, ou stockage d’archive inactive pour la conservation à long terme. Chacun possède ses propres caractéristiques de performance et de résilience, ses SLA et sa grille tarifaire. Des structures de frais complexes avec de multiples variables tarifaires rendent difficile la prise de décisions éclairées, la prévision des coûts et la gestion des budgets.
Verrouillage fournisseur
Chaque fournisseur de services prend en charge une API unique. Changer de service est long et coûteux : vous devez réécrire ou remplacer vos outils et applications de gestion du stockage existants. Pire encore, les fournisseurs historiques facturent des frais de transfert de données (egress) excessifs pour sortir les données de leurs clouds, ce qui rend coûteux le changement de fournisseur ou l’utilisation d’un mix de fournisseurs.
Attention aux services de stockage par paliers
Les fournisseurs cloud de stockage de première génération proposent des services de stockage par paliers déroutants. Chaque palier est destiné à un type de données spécifique et présente des caractéristiques de performance, des SLA et des plans tarifaires distincts (avec des structures de frais complexes).
Bien que le portefeuille de chaque fournisseur diffère légèrement, ces services par paliers sont généralement optimisés pour trois classes distinctes de données.
Données actives
Données en ligne facilement accessibles par le système d’exploitation, une application ou les utilisateurs. Les données actives sont fréquemment consultées et exigent des performances strictes en lecture/écriture.
Archive active
Données consultées occasionnellement mais disponibles instantanément en ligne (sans restauration ni réhydratation depuis une source hors ligne ou distante). Exemples : données de sauvegarde pour une reprise rapide après sinistre ou gros fichiers vidéo susceptibles d’être consultés ponctuellement à court préavis.
Archive inactive
Données rarement consultées. Exemples : données conservées à long terme pour la conformité réglementaire. Historiquement, les données inactives sont archivées sur bande et stockées hors site.
Identifier la meilleure classe de stockage (et le meilleur rapport qualité-prix) pour une application donnée peut être un véritable défi avec un fournisseur cloud historique. Microsoft Azure, par exemple, propose quatre options distinctes de stockage objet : General Purpose v1, General Purpose v2, Blob Storage et Premium Blob Storage. Chaque option possède des caractéristiques tarifaires et de performance propres. Et certaines options (mais pas toutes) prennent en charge trois paliers de stockage distincts, avec des SLA et des frais différents : stockage hot (pour les données fréquemment consultées), stockage cool (pour les données peu consultées) et stockage archive (pour les données rarement consultées). Avec autant de choix et de variables tarifaires, il est presque impossible de prendre une décision réellement éclairée et de budgéter précisément les dépenses.
Chez IDrive® e2, nous pensons que le stockage cloud doit être simple. Contrairement aux services de stockage cloud historiques avec des paliers confus et des modèles tarifaires alambiqués, nous proposons un produit unique — avec une tarification prévisible, abordable et transparente — qui répond à tout besoin de stockage cloud. Vous pouvez utiliser IDrive® e2 pour n’importe quelle classe de données : données actives, archive active et archive inactive.
Stockage cloud hot IDrive® e2 pour les lacs de données
Le stockage cloud hot IDrive® e2 est un stockage objet cloud extrêmement économique, rapide et fiable pour tous les usages. Contrairement aux services de stockage cloud de première génération avec des paliers confus et des schémas tarifaires complexes, IDrive® e2 est facile à comprendre et très rentable à faire évoluer. IDrive® e2 est idéal pour stocker des volumes massifs de données brutes.
Les principaux avantages d’IDrive® e2 pour les lacs de données incluent :
Tarification standard
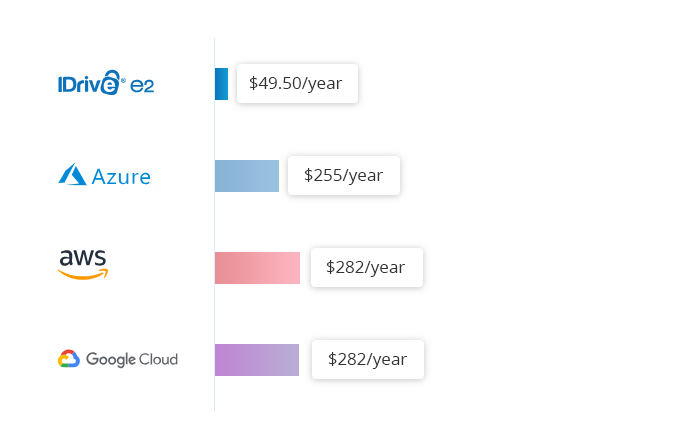
Le stockage cloud hot IDrive® e2 coûte un tarif fixe de 0,004 $/Go/mois. Comparez cela à 0,023 $/Go/mois pour Amazon S3 Standard, 0,026 $/Go/mois pour Google Multi-Regional et 0,046 $/Go/mois pour Azure RA-GRS Hot.
Contrairement à AWS, Microsoft Azure et Google Cloud Platform, nous n’imposons pas de frais supplémentaires pour récupérer les données du stockage (frais d’egress). Nous ne facturons pas non plus de frais supplémentaires pour les appels API.
Performances supérieures
L’architecture système parallélisée d’IDrive® e2 offre des performances de lecture/écriture plus rapides que les services de stockage cloud de première génération, avec des temps de réponse au premier octet nettement plus courts.
Durabilité et protection robustes des données
Le stockage cloud hot IDrive® e2 est conçu pour offrir une durabilité, une intégrité et une sécurité des données extrêmes. Une fonctionnalité optionnelle d’immuabilité des données empêche les suppressions accidentelles et les erreurs administratives, protège contre les malwares, bugs et virus, et améliore la conformité réglementaire.
Stockage cloud hot IDrive® e2 pour les lacs de données Apache Hadoop
Si vous exécutez votre lac de données sur Apache Hadoop, vous pouvez utiliser le stockage cloud hot IDrive® e2 comme alternative économique à HDFS, comme illustré dans le schéma ci-dessous. Le stockage cloud hot IDrive® e2 est entièrement compatible avec l’API AWS S3. Vous pouvez utiliser le connecteur Hadoop Amazon S3A, qui fait partie de la distribution open source Apache Hadoop, pour intégrer Amazon S3 et d’autres stockages cloud compatibles comme IDrive® e2 dans divers flux MapReduce.
Vous pouvez utiliser le stockage cloud hot IDrive® e2 dans le cadre d’une implémentation de lac de données multi-cloud afin d’élargir vos choix et d’éviter le verrouillage fournisseur. Une approche multi-cloud vous permet de faire évoluer indépendamment les ressources de calcul et de stockage du lac de données, en utilisant les meilleurs fournisseurs.
Vous pouvez également connecter votre cloud privé directement à IDrive® e2. Contrairement aux fournisseurs de stockage cloud de première génération, avec IDrive® e2 vous ne payez jamais de frais de transfert de données (egress). En d’autres termes, vous pouvez déplacer librement vos données hors d’IDrive® e2.
Continuité d’activité et reprise après sinistre économiques
IDrive® e2 est hébergé dans plusieurs centres de données géographiquement répartis pour la résilience et la haute disponibilité. Vous pouvez répliquer les données entre les régions IDrive® e2 pour la continuité d’activité, la reprise après sinistre et la protection des données, comme indiqué ci-dessous.
Par exemple, vous pouvez répliquer les données entre trois centres de données (régions) IDrive® e2 :
- Centre de données IDrive® e2 1 pour le stockage de données actives (stockage principal).
- Centre de données IDrive® e2 2 comme archive active pour la sauvegarde et la reprise (secours à chaud en cas d’indisponibilité du centre de données 1).
- Centre de données IDrive® e2 3 comme magasin de données immuable (pour protéger les données contre les erreurs administratives, les suppressions accidentelles et les ransomwares). Un objet de données immuable ne peut être ni supprimé ni modifié par quiconque, y compris IDrive® e2.