Data Warehouse vs Data Mart vs Data Lake
Die Begriffe Data Lake und Data Warehouse werden oft verwechselt und manchmal synonym verwendet. Tatsächlich werden beide zur Speicherung großer Datenmengen genutzt, aber Data Lakes und Data Warehouses sind unterschiedlich (und können sich ergänzen).
- Data Lake – ist ein riesiger Pool von Daten, der jede Art von Daten enthalten kann – strukturiert, semi-strukturiert oder unstrukturiert.
- Data Warehouse – ist ein Repository für strukturierte, gefilterte Daten, die bereits für einen bestimmten Zweck verarbeitet wurden. Mit anderen Worten: Ein Data Warehouse ist gut organisiert und enthält klar definierte Daten.
- Data Mart – ist ein Teilbereich eines Data Warehouse, der von einer bestimmten Geschäftseinheit für einen bestimmten Zweck genutzt wird, z. B. für eine Anwendung im Lieferkettenmanagement.
James Dixon, der den Begriff Data Lake geprägt hat, erklärt die Unterschiede mit einer Analogie: „Wenn Sie sich einen Data Mart als einen Laden mit abgefülltem Wasser vorstellen – gereinigt, verpackt und strukturiert für den einfachen Verbrauch – dann ist der Data Lake ein großes Gewässer in einem natürlicheren Zustand. Der Inhalt des Data Lake fließt aus einer Quelle in den See, und verschiedene Nutzer können den See untersuchen, eintauchen oder Proben entnehmen.“
Ein Data Lake kann zusammen mit einem Data Warehouse verwendet werden. Beispielsweise können Sie einen Data Lake als Zwischen- und Staging-Repository für ein Data Warehouse nutzen. Sie können den Data Lake verwenden, um Daten zu kuratieren oder zu bereinigen, bevor Sie sie in ein Data Warehouse oder andere Datenstrukturen einspeisen.
Data Lakes, die nicht kuratiert werden, laufen Gefahr, zu Data Swamps zu werden, in denen keine Governance- oder Qualitätsentscheidungen auf die Daten angewendet werden. Dadurch sinkt der Wert der Datensammlung erheblich, da gemischte Qualitätsdaten so zusammengeführt werden, dass es schwierig wird, sich auf die Gültigkeit der daraus abgeleiteten Entscheidungen zu verlassen.
Das folgende Diagramm zeigt einen typischen Technologie-Stack für Data Lakes. Der Data Lake umfasst skalierbare Speicher- und Rechenressourcen, Datenverarbeitungstools für das Datenmanagement, Analyse- und Reporting-Tools für Datenwissenschaftler, Geschäftsanwender und technisches Personal sowie gemeinsame Systeme für Data Governance, Sicherheit und Betrieb.
Sie können einen Data Lake im eigenen Rechenzentrum oder in der Cloud implementieren. Viele frühe Anwender haben Data Lakes lokal bereitgestellt. Da Data Lakes immer häufiger eingesetzt werden, suchen viele Unternehmen nach Cloud-basierten Data Lakes, um die Time-to-Value zu verkürzen, die Gesamtbetriebskosten zu senken und die geschäftliche Agilität zu verbessern.
Lokale Data Lakes sind CAPEX- und OPEX-intensiv
Sie können einen Data Lake im eigenen Rechenzentrum mit Standardservern und lokalem (internem) Speicher implementieren. Heute nutzen die meisten lokalen Data Lakes eine kommerzielle oder Open-Source-Version von Hadoop als Datenplattform. (In der TDWI-Umfrage nutzen 53 % der Befragten Hadoop als Datenplattform, während nur 6 % ein relationales Datenbankmanagementsystem verwenden.)
Sie können Hunderte oder Tausende von Servern kombinieren, um einen skalierbaren und ausfallsicheren Hadoop-Cluster zu erstellen, der in der Lage ist, große Datensätze zu speichern und zu verarbeiten. Das folgende Diagramm zeigt einen Technologie-Stack für einen lokalen Data Lake auf Apache Hadoop.
Der Technologie-Stack umfasst:
-
Hadoop MapReduce:
Ein Software-Framework zum einfachen Schreiben von Anwendungen, die große Datenmengen parallel auf großen Clustern von Standardhardware zuverlässig und fehlertolerant verarbeiten.
-
Hadoop YARN:
Ein Framework für Job-Scheduling und Ressourcenmanagement im Cluster.
-
Hadoop Distributed File System (HDFS):
Ein Hochleistungs-Dateisystem, das speziell für den Betrieb auf kostengünstigen Servern mit preiswerten internen Festplatten entwickelt wurde.
Lokale Data Lakes bieten hohe Leistung und starke Sicherheit, sind jedoch bekanntermaßen teuer und kompliziert in der Bereitstellung, Verwaltung, Wartung und Skalierung. Nachteile eines lokalen Data Lake sind:
Langwierige Installation
Der Aufbau eines eigenen Data Lake erfordert erheblichen Zeit-, Arbeits- und Kostenaufwand. Sie müssen das System entwerfen und konzipieren, Sicherheits- und Verwaltungssysteme sowie Best Practices definieren und einführen, die Infrastruktur für Rechenleistung, Speicher und Netzwerk beschaffen, aufbauen und testen sowie alle Softwarekomponenten identifizieren, installieren und konfigurieren. Es dauert in der Regel Monate (oft über ein Jahr), bis ein lokaler Data Lake produktiv läuft.
Hohe Investitionskosten (CAPEX)
Erhebliche Anfangsinvestitionen in die Ausrüstung führen zu unausgewogenen Geschäftsmodellen mit schlechter Kapitalrendite und langen Amortisationszeiten. Server, Festplatten und Netzwerkinfrastruktur werden überdimensioniert, um Spitzenlasten und zukünftige Kapazitätsanforderungen zu erfüllen, sodass Sie immer für ungenutzte Ressourcen zahlen.
Hohe Betriebskosten (OPEX)
Laufende Kosten für Strom, Kühlung und Rackplatz, monatliche Wartungs- und Supportgebühren sowie laufende Verwaltungskosten führen zu hohen Betriebsausgaben.
Hohes Risiko
Die Sicherstellung der Geschäftskontinuität (Replikation von Live-Daten in ein zweites Rechenzentrum) ist eine teure Angelegenheit, die für die meisten Unternehmen nicht erschwinglich ist. Viele Unternehmen sichern Daten auf Band oder Festplatte. Im Katastrophenfall kann es Tage oder sogar Wochen dauern, bis Systeme wiederhergestellt und der Betrieb aufgenommen werden kann.
Komplexe Systemadministration
Der Betrieb eines lokalen Data Lake ist ressourcenintensiv und bindet wertvolle (und teure) IT-Mitarbeiter, die für strategischere Aufgaben benötigt werden.
Cloud Data Lakes eliminieren Kosten und Komplexität
Sie können einen Data Lake in einer Public Cloud implementieren, um Ausrüstungskosten und -aufwand zu vermeiden und Big-Data-Initiativen zu beschleunigen. Die allgemeinen Vorteile eines Cloud-basierten Data Lake sind:
Schnelle Wertschöpfung
Sie können die Einführungszeit von Monaten auf Wochen verkürzen, indem Sie Infrastrukturdesign und Hardwarebeschaffung, -installation und -inbetriebnahme eliminieren.
Keine Investitionskosten
Sie vermeiden Anfangsinvestitionen, passen die Ausgaben besser an die Geschäftsanforderungen an und schaffen Kapital für andere Programme frei.
Keine Betriebskosten für Ausrüstung
Sie eliminieren laufende Betriebskosten für Ausrüstung (Strom, Kühlung, Immobilien), jährliche Wartungsgebühren und wiederkehrende Verwaltungskosten.
Sofortige und unbegrenzte Skalierbarkeit
Sie können Rechen- und Speicherkapazität nach Bedarf hinzufügen, um sich schnell ändernden Geschäftsanforderungen gerecht zu werden und die Kundenzufriedenheit zu verbessern.
Unabhängige Skalierung
Im Gegensatz zu einer lokalen Hadoop-Implementierung, die auf Servern mit internem Speicher basiert, können Sie bei einer Cloud-Implementierung Rechen- und Speicherkapazität unabhängig voneinander skalieren, um Kosten zu optimieren und Ressourcen optimal zu nutzen.
Geringeres Risiko
Sie können Daten über Regionen hinweg replizieren, um die Ausfallsicherheit zu erhöhen und die ständige Verfügbarkeit im Katastrophenfall sicherzustellen.
Vereinfachter Betrieb
Sie entlasten das IT-Personal, damit es sich auf strategische Aufgaben konzentrieren kann (der Cloud-Anbieter verwaltet die physische Infrastruktur).
Cloud-Speicherdienste der ersten Generation sind zu teuer und komplex für Data Lakes
Im Vergleich zu einem lokalen Data Lake ist ein Cloud-basierter Data Lake viel einfacher und kostengünstiger bereitzustellen, zu skalieren und zu betreiben. Dennoch sind Cloud-Objektspeicherdienste der ersten Generation wie AWS S3, Microsoft Azure Blob Storage und Google Cloud Platform Storage von Natur aus teuer (in vielen Fällen genauso teuer wie lokale Speicherlösungen) und kompliziert. Viele Unternehmen suchen nach einfacheren, erschwinglicheren Speicherdiensten für Data Lake-Initiativen. Einschränkungen von Cloud-Objektspeicherdiensten der ersten Generation sind:
Teure und verwirrende Servicestufen
Traditionelle Cloud-Anbieter verkaufen verschiedene Arten (Stufen) von Speicherdiensten. Jede Stufe ist für einen bestimmten Zweck vorgesehen, z. B. Primärspeicher für aktive Daten, aktives Archiv für Notfallwiederherstellung oder inaktives Archiv für langfristige Datenaufbewahrung. Jede Stufe hat eigene Leistungs- und Ausfallsicherheitsmerkmale, SLAs und Preisstrukturen. Komplizierte Gebührenstrukturen mit mehreren Preisvariablen erschweren es, fundierte Entscheidungen zu treffen, Kosten zu prognostizieren und Budgets zu verwalten.
Anbieterbindung
Jeder Dienstanbieter unterstützt eine eigene API. Ein Wechsel des Dienstes ist teuer und zeitaufwendig – Sie müssen Ihre bestehenden Speicherverwaltungstools und Apps umschreiben oder austauschen. Noch schlimmer: Traditionelle Anbieter verlangen hohe Gebühren für den Datentransfer (Egress), um Daten aus ihrer Cloud zu verschieben, was den Wechsel zu anderen Anbietern oder die Nutzung mehrerer Anbieter teuer macht.
Vorsicht bei gestuften Speicherdiensten
Cloud-Speicheranbieter der ersten Generation bieten verwirrende gestufte Speicherdienste an. Jede Speicherstufe ist für einen bestimmten Datentyp vorgesehen und hat eigene Leistungsmerkmale, SLAs und Preispläne (mit komplexen Gebührenstrukturen).
Obwohl das Portfolio jedes Anbieters leicht unterschiedlich ist, sind diese gestuften Dienste im Allgemeinen für drei verschiedene Datenklassen optimiert.
Aktive Daten
Live-Daten, die vom Betriebssystem, einer Anwendung oder Benutzern direkt abgerufen werden können. Aktive Daten werden häufig abgerufen und haben hohe Anforderungen an die Lese-/Schreibgeschwindigkeit.
Aktives Archiv
Gelegentlich abgerufene Daten, die sofort online verfügbar sind (nicht aus einer Offline- oder Remote-Quelle wiederhergestellt werden müssen). Beispiele sind Sicherungsdaten für schnelle Notfallwiederherstellung oder große Videodateien, die gelegentlich kurzfristig abgerufen werden.
Inaktives Archiv
Selten abgerufene Daten. Beispiele sind Daten, die langfristig aus regulatorischen Gründen aufbewahrt werden. Historisch wurden inaktive Daten auf Band archiviert und extern gelagert.
Die Auswahl der besten Speicherklasse (und des besten Preis-Leistungs-Verhältnisses) für eine bestimmte Anwendung kann bei einem traditionellen Cloud-Speicheranbieter eine echte Herausforderung sein. Microsoft Azure bietet beispielsweise vier verschiedene Optionen für Objektspeicher: General Purpose v1, General Purpose v2, Blob Storage und Premium Blob Storage. Jede Option hat eigene Preis- und Leistungsmerkmale. Und einige (aber nicht alle) Optionen unterstützen drei verschiedene Speicherstufen mit eigenen SLAs und Gebühren: Hot Storage (für häufig abgerufene Daten), Cool Storage (für selten abgerufene Daten) und Archive Storage (für sehr selten abgerufene Daten). Bei so vielen Auswahlmöglichkeiten und Preisvariablen ist es nahezu unmöglich, eine fundierte Entscheidung zu treffen und die Kosten genau zu kalkulieren.
Bei IDrive® e2 sind wir der Meinung, dass Cloud-Speicher einfach sein sollte. Im Gegensatz zu traditionellen Cloud-Speicherdiensten mit verwirrenden Speicherebenen und komplizierten Preisstrukturen bieten wir ein einziges Produkt – mit vorhersehbaren, erschwinglichen und transparenten Preisen –, das jede Cloud-Speicheranforderung erfüllt. Sie können IDrive® e2 für jede Speicherklasse verwenden: aktive Daten, aktives Archiv und inaktives Archiv.
IDrive® e2 Hot Cloud Storage für Data Lakes
IDrive® e2 Hot Cloud Storage ist ein äußerst wirtschaftlicher, schneller und zuverlässiger Cloud-Objektspeicher für jeden Zweck. Im Gegensatz zu Cloud-Speicherdiensten der ersten Generation mit verwirrenden Speicherebenen und komplexen Preisstrukturen ist IDrive® e2 einfach zu verstehen und äußerst kosteneffizient zu skalieren. IDrive® e2 eignet sich ideal zur Speicherung großer Mengen an Rohdaten.
Die wichtigsten Vorteile von IDrive® e2 für Data Lakes sind:
Günstige Preise
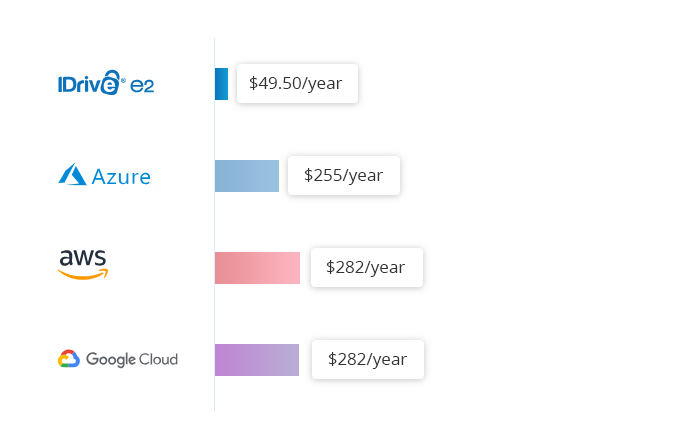
IDrive® e2 Hot Cloud Storage kostet pauschal 0,004 $/GB/Monat. Zum Vergleich: 0,023 $/GB/Monat für Amazon S3 Standard, 0,026 $/GB/Monat für Google Multi-Regional und 0,046 $/GB/Monat für Azure RA-GRS Hot.
Im Gegensatz zu AWS, Microsoft Azure und Google Cloud Platform erheben wir keine zusätzlichen Gebühren für das Abrufen von Daten aus dem Speicher (Egress-Gebühren). Wir berechnen auch keine zusätzlichen Gebühren für API-Aufrufe.
Überlegene Leistung
Die parallelisierte Systemarchitektur von IDrive® e2 bietet schnellere Lese-/Schreibleistungen als Cloud-Speicherdienste der ersten Generation, mit deutlich schnelleren Time-to-First-Byte-Geschwindigkeiten.
Hohe Datensicherheit und Schutz
IDrive® e2 Hot Cloud Storage wurde entwickelt, um höchste Datensicherheit, Integrität und Schutz zu bieten. Eine optionale Datenunveränderlichkeitsfunktion verhindert versehentliche Löschungen und administrative Fehler, schützt vor Malware, Bugs und Viren und verbessert die Einhaltung gesetzlicher Vorschriften.
IDrive® e2 Hot Cloud Storage für Apache Hadoop Data Lakes
Wenn Sie Ihren Data Lake auf Apache Hadoop betreiben, können Sie IDrive® e2 Hot Cloud Storage als kostengünstige Alternative zu HDFS nutzen, wie im folgenden Diagramm dargestellt. IDrive® e2 Hot Cloud Storage ist vollständig kompatibel mit der AWS S3 API. Sie können den Hadoop Amazon S3A Connector, der Teil der Open-Source-Distribution von Apache Hadoop ist, verwenden, um Amazon S3 und andere kompatible Cloud-Speicher wie IDrive® e2 in verschiedene MapReduce-Flows zu integrieren.
Sie können IDrive® e2 Hot Cloud Storage als Teil einer Multi-Cloud-Data-Lake-Implementierung nutzen, um mehr Auswahlmöglichkeiten zu haben und Anbieterbindung zu vermeiden. Ein Multi-Cloud-Ansatz ermöglicht es Ihnen, Rechen- und Speicherressourcen für den Data Lake unabhängig voneinander zu skalieren und die besten Anbieter zu nutzen.
Sie können auch Ihre Private Cloud direkt mit IDrive® e2 verbinden. Im Gegensatz zu Cloud-Speicheranbietern der ersten Generation zahlen Sie bei IDrive® e2 niemals Gebühren für den Datentransfer (Egress). Das heißt, Sie können Daten frei aus IDrive® e2 verschieben.
Wirtschaftliche Geschäftskontinuität und Notfallwiederherstellung
IDrive® e2 wird in mehreren, geografisch verteilten Rechenzentren für Ausfallsicherheit und hohe Verfügbarkeit gehostet. Sie können Daten über verschiedene IDrive® e2-Regionen hinweg replizieren, um Geschäftskontinuität, Notfallwiederherstellung und Datenschutz zu gewährleisten, wie unten dargestellt.
Beispielsweise können Sie Daten über drei verschiedene IDrive® e2-Rechenzentren (Regionen) replizieren:
- IDrive® e2 Rechenzentrum 1 für aktive Datenspeicherung (Primärspeicher).
- IDrive® e2 Rechenzentrum 2 als aktives Archiv für Backup und Wiederherstellung (Hot Standby, falls Rechenzentrum 1 nicht erreichbar ist).
- IDrive® e2 Rechenzentrum 3 als unveränderlicher Datenspeicher (zum Schutz vor administrativen Fehlern, versehentlichen Löschungen und Ransomware). Ein unveränderliches Datenobjekt kann von niemandem gelöscht oder geändert werden, auch nicht von IDrive® e2.