Data Warehouse vs Data Mart vs Data Lake
Os termos data lake e data warehouse são frequentemente confundidos e às vezes usados de forma intercambiável. Na verdade, embora ambos sejam usados para armazenar grandes conjuntos de dados, data lakes e data warehouses são diferentes (e podem ser complementares).
- Data Lake - é um enorme pool de dados que pode conter qualquer tipo de dado — estruturado, semiestruturado ou não estruturado.
- Data warehouse - é um repositório para dados estruturados e filtrados que já foram processados para uma finalidade específica. Em outras palavras, um data warehouse é bem organizado e contém dados bem definidos.
- Data mart - é um subconjunto de um data warehouse, usado por uma unidade de negócios empresarial específica para uma finalidade específica, como um aplicativo de gerenciamento da cadeia de suprimentos.
James Dixon, o criador do termo data lake, explica as diferenças por analogia: "Se você pensar em um data mart como uma loja de água engarrafada — limpa, embalada e estruturada para fácil consumo — o data lake é um grande corpo de água em estado mais natural. O conteúdo do data lake flui de uma fonte para encher o lago, e vários usuários do lago podem vir para examinar, mergulhar ou coletar amostras."
Um data lake pode ser usado em conjunto com um data warehouse. Por exemplo, você pode usar um data lake como repositório de pouso e preparação para um data warehouse. Você pode usar o data lake para selecionar ou limpar dados antes de alimentá-los em um data warehouse ou outras estruturas de dados.
Data lakes que não são curados correm o risco de se tornarem pântanos de dados sem governança ou decisões de qualidade aplicadas aos dados, diminuindo radicalmente o valor da coleta de dados ao "turvar" dados de qualidade mista de uma forma que dificulta confiar na validade das decisões tomadas a partir dos dados coletados.
O diagrama a seguir representa uma pilha de tecnologia típica de data lake. O data lake inclui recursos de armazenamento e computação escaláveis; ferramentas de processamento de dados para gerenciar dados; ferramentas de análise e relatórios para cientistas de dados, usuários de negócios e pessoal técnico; e sistemas comuns de governança de dados, segurança e operações.
Você pode implementar um data lake em um data center corporativo ou na nuvem. Muitos dos primeiros adotantes implantaram data lakes no local. À medida que os data lakes se tornam mais prevalentes, muitos adotantes convencionais estão buscando data lakes baseados em nuvem para acelerar o tempo de valorização, reduzir o TCO e melhorar a agilidade dos negócios.
Data Lakes Locais são Intensivos em CAPEX e OPEX
Você pode implementar um data lake em um data center corporativo usando servidores de commodity e armazenamento local (interno). Hoje, a maioria dos data lakes locais usa uma versão comercial ou de código aberto do Hadoop, um popular framework de computação de alto desempenho, como plataforma de dados. (Na pesquisa TDWI, 53% dos entrevistados estão usando o Hadoop como plataforma de dados, enquanto apenas 6% estão usando um sistema de gerenciamento de banco de dados relacional.)
Você pode combinar centenas ou milhares de servidores para criar um cluster Hadoop escalável e resiliente, capaz de armazenar e processar conjuntos de dados massivos. O diagrama abaixo representa uma pilha de tecnologia para um data lake local no Apache Hadoop.
A pilha de tecnologia inclui:
-
Hadoop MapReduce:
Um framework de software para escrever facilmente aplicativos que processam grandes volumes de dados em paralelo em grandes clusters de hardware de commodity de maneira confiável e tolerante a falhas.
-
Hadoop YARN:
Um framework para agendamento de tarefas e gerenciamento de recursos de cluster.
-
Sistema de Arquivos Distribuído Hadoop (HDFS):
Um sistema de arquivos de alto desempenho especificamente projetado para funcionar em servidores de baixo custo, com unidades de disco internas baratas.
Os data lakes locais oferecem alto desempenho e segurança robusta, mas são notoriamente caros e complicados de implantar, administrar, manter e escalar. As desvantagens de um data lake local incluem:
Instalação prolongada
Construir seu próprio data lake requer tempo, esforço e dinheiro significativos. Você precisa projetar e arquitetar o sistema; definir e instituir sistemas de segurança e administrativos e melhores práticas; adquirir, configurar e testar a infraestrutura de computação, armazenamento e rede; e identificar, instalar e configurar todos os componentes de software. Normalmente leva meses (muitas vezes mais de um ano) para colocar um data lake local em produção.
Alto CAPEX
Os gastos iniciais substanciais com equipamentos levam a modelos de negócios desequilibrados com baixo ROI e longos períodos de retorno. Servidores, discos e infraestrutura de rede são todos superprojetados para atender às demandas de tráfego de pico e requisitos futuros de capacidade, portanto, você sempre está pagando por recursos de computação ociosos e capacidade de armazenamento e rede não utilizadas.
Alto OPEX
Despesas recorrentes de energia, refrigeração e espaço em rack; taxas mensais de manutenção de hardware e suporte de software; e custos contínuos de administração de hardware levam a altas despesas operacionais de equipamentos.
Alto risco
Garantir a continuidade dos negócios (replicar dados ativos para um data center secundário) é uma proposição cara além do alcance da maioria das empresas. Muitas empresas fazem backup de dados em fita ou disco. Em caso de catástrofe, pode levar dias ou até semanas para reconstruir sistemas e restaurar operações.
Administração complexa de sistema
Executar um data lake local é uma proposição intensiva em recursos que desvia pessoal de TI valioso (e caro) de empreendimentos mais estratégicos.
Data Lakes em Nuvem Eliminam Custos e Complexidade de Equipamentos
Você pode implementar um data lake em uma nuvem pública para evitar despesas e complicações com equipamentos e acelerar iniciativas de big data. As vantagens gerais de um data lake baseado em nuvem incluem:
Rápido tempo de valorização
Você pode reduzir os tempos de implantação de meses para semanas, eliminando esforços de design de infraestrutura e tarefas de aquisição, instalação e ativação de hardware.
Sem CAPEX
Você pode evitar gastos iniciais de capital, alinhar melhor as despesas com os requisitos de negócios e liberar orçamento de capital para outros programas.
Sem despesas operacionais de equipamentos
Você pode eliminar as despesas operacionais contínuas de equipamentos (energia, refrigeração, imóveis), taxas anuais de manutenção de hardware e custos recorrentes de administração de sistemas.
Escalabilidade instantânea e infinita
Você pode adicionar capacidade de computação e armazenamento sob demanda para atender aos requisitos de negócios em rápida evolução e melhorar a satisfação do cliente (responder rapidamente aos requisitos de linha de negócios).
Escalabilidade independente
Ao contrário de uma implementação Hadoop local que depende de servidores com armazenamento interno, com uma implementação em nuvem você pode escalar a capacidade de computação e armazenamento de forma independente para otimizar custos e maximizar o uso de recursos.
Menor risco
Você pode replicar dados entre regiões para melhorar a resiliência e garantir disponibilidade contínua em caso de catástrofe.
Operações simplificadas
Você pode liberar a equipe de TI para se concentrar em tarefas estratégicas de suporte aos negócios (o provedor de nuvem gerencia a infraestrutura física).
Serviços de Armazenamento em Nuvem de Primeira Geração são Caros e Complexos Demais para Data Lakes
Comparado a um data lake local, um data lake baseado em nuvem é muito mais fácil e menos caro de implantar, escalar e operar. Dito isso, os serviços de armazenamento de objetos em nuvem de primeira geração, como AWS S3, Microsoft Azure Blob Storage e Google Cloud Platform Storage, são inerentemente caros (em muitos casos sendo tão caros quanto as soluções de armazenamento locais) e complicados. Muitas empresas estão buscando serviços de armazenamento mais simples e acessíveis para iniciativas de data lake. As limitações dos serviços de armazenamento de objetos em nuvem de primeira geração incluem:
Níveis de serviço caros e confusos
Os fornecedores de nuvem legados vendem vários tipos (níveis) diferentes de serviços de armazenamento. Cada nível destina-se a uma finalidade distinta, por exemplo, armazenamento primário para dados ativos, armazenamento de arquivamento ativo para recuperação de desastres ou armazenamento de arquivamento inativo para retenção de dados a longo prazo. Cada um tem características únicas de desempenho e resiliência, SLAs e cronogramas de preços. Estruturas de taxas complicadas com múltiplas variáveis de preços dificultam fazer escolhas bem informadas, prever custos e gerenciar orçamentos.
Bloqueio de fornecedor
Cada provedor de serviços suporta uma API exclusiva. Mudar de serviços é uma proposição cara e demorada — você precisa reescrever ou substituir suas ferramentas e aplicativos de gerenciamento de armazenamento existentes. Pior ainda, os fornecedores legados cobram taxas excessivas de transferência de dados (saída) para mover dados para fora de suas nuvens, tornando caro mudar de provedor ou aproveitar uma mistura de provedores.
Cuidado com os Serviços de Armazenamento em Camadas
Os provedores de armazenamento em nuvem de primeira geração oferecem serviços de armazenamento em camadas confusos. Cada camada de armazenamento destina-se a um tipo específico de dado e tem características de desempenho distintas, SLAs e planos de preços (com estruturas de taxas complexas).
Embora o portfólio de cada fornecedor seja ligeiramente diferente, esses serviços em camadas são geralmente otimizados para três classes distintas de dados.
Dados Ativos
Dados ativos que são prontamente acessíveis pelo sistema operacional, um aplicativo ou usuários. Os dados ativos são frequentemente acessados e têm requisitos rigorosos de desempenho de leitura/gravação.
Arquivo Ativo
Dados acessados ocasionalmente que estão disponíveis instantaneamente online (não restaurados e reidratados de uma fonte offline ou remota). Os exemplos incluem dados de backup para recuperação rápida de desastres ou grandes arquivos de vídeo que podem ser acessados de tempos em tempos com pouco aviso.
Arquivo Inativo
Dados acessados com pouca frequência. Os exemplos incluem dados mantidos por longo prazo para conformidade regulatória. Historicamente, os dados inativos são arquivados em fita e armazenados externamente.
Identificar a melhor classe de armazenamento (e melhor valor) para um aplicativo específico pode ser um verdadeiro desafio com um provedor de armazenamento em nuvem legado. A Microsoft Azure, por exemplo, oferece quatro opções distintas de armazenamento de objetos: General Purpose v1, General Purpose v2, Blob Storage e Premium Blob Storage. Cada opção tem características únicas de preços e desempenho. E algumas (mas não todas) das opções suportam três camadas de armazenamento distintas, com SLAs e taxas distintas: armazenamento quente (para dados frequentemente acessados), armazenamento frio (para dados raramente acessados) e armazenamento de arquivo (para dados raramente acessados). Com tantas escolhas e variáveis de preços, é quase impossível tomar uma decisão bem informada e orçar com precisão as despesas.
Na IDrive® e2, acreditamos que o armazenamento em nuvem deve ser simples. Ao contrário dos serviços de armazenamento em nuvem legados com camadas de armazenamento confusas e esquemas de preços complicados, oferecemos um único produto — com preços previsíveis, acessíveis e diretos — que satisfaz qualquer requisito de armazenamento em nuvem. Você pode usar IDrive® e2 para qualquer classe de armazenamento de dados: dados ativos, arquivo ativo e arquivo inativo.
Armazenamento em Nuvem Quente IDrive® e2 para Data Lakes
O armazenamento em nuvem quente IDrive® e2 é um armazenamento de objetos em nuvem extremamente econômico, rápido e confiável para qualquer finalidade. Ao contrário dos serviços de armazenamento em nuvem de primeira geração com camadas de armazenamento confusas e esquemas de preços complexos, IDrive® e2 é fácil de entender e extremamente econômico para escalar. IDrive® e2 é ideal para armazenar grandes volumes de dados brutos.
As principais vantagens do IDrive® e2 para data lakes incluem:
Preços de commodity
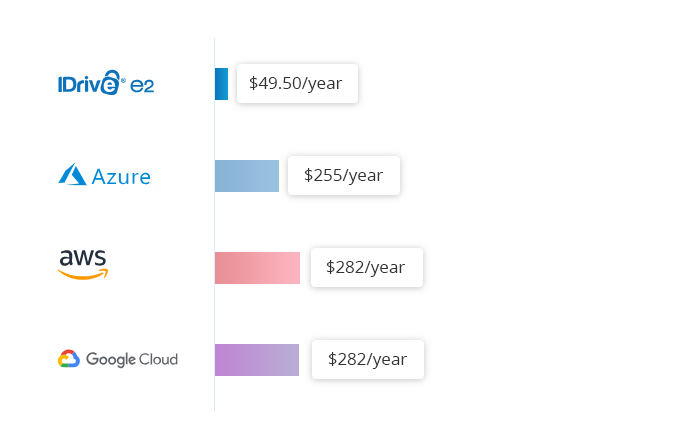
O armazenamento em nuvem quente IDrive® e2 custa uma taxa fixa de $0,004/GB/mês. Compare isso com $0,023/GB/mês para Amazon S3 Standard, $0,026/GB/mês para Google Multi-Regional e $0,046/GB/mês para Azure RA-GRS Hot.
Ao contrário da AWS, Microsoft Azure e Google Cloud Platform, não impomos taxas extras para recuperar dados do armazenamento (taxas de saída). Também não cobramos taxas extras por chamadas de API.
Desempenho superior
A arquitetura de sistema paralelizado do IDrive® e2 oferece desempenhos de leitura/gravação mais rápidos do que os serviços de armazenamento em nuvem de primeira geração, com velocidades de tempo de primeiro byte significativamente mais rápidas.
Durabilidade e proteção de dados robustas
O armazenamento em nuvem quente IDrive® e2 foi construído para oferecer extrema durabilidade, integridade e segurança de dados. Uma capacidade opcional de imutabilidade de dados evita exclusões acidentais e erros administrativos; protege contra malware, bugs e vírus; e melhora a conformidade regulatória.
Armazenamento em Nuvem Quente IDrive® e2 para Data Lakes Apache Hadoop
Se você executa seu data lake no Apache Hadoop, pode usar o armazenamento em nuvem quente IDrive® e2 como uma alternativa acessível ao HDFS, conforme mostrado no diagrama abaixo. O armazenamento em nuvem quente IDrive® e2 é totalmente compatível com a API AWS S3. Você pode usar o conector Hadoop Amazon S3A, parte da distribuição Apache Hadoop de código aberto, para integrar o Amazon S3 e outro armazenamento em nuvem compatível como IDrive® e2 em vários fluxos MapReduce.
Você pode usar o armazenamento em nuvem quente IDrive® e2 como parte de uma implementação de data lake multi-nuvem para melhorar a escolha e evitar o bloqueio de fornecedor. Uma abordagem multi-nuvem permite que você escale os recursos de computação e armazenamento do data lake de forma independente, usando provedores de ponta.
Você também pode conectar sua nuvem privada diretamente ao IDrive® e2. Ao contrário dos provedores de armazenamento em nuvem de primeira geração, com IDrive® e2 você nunca paga taxas de transferência de dados (saída). Em outras palavras, você pode mover dados livremente para fora do IDrive® e2.
Continuidade de Negócios e Recuperação de Desastres Econômicas
IDrive® e2 é hospedado em vários data centers geograficamente distribuídos para resiliência e alta disponibilidade. Você pode replicar dados entre regiões IDrive® e2 para continuidade de negócios, recuperação de desastres e proteção de dados, conforme mostrado abaixo.
Por exemplo, você pode replicar dados em três data centers (regiões) IDrive® e2 diferentes usando:
- IDrive® e2 Data Center 1 para armazenamento de dados ativos (armazenamento primário).
- IDrive® e2 Data Center 2 como arquivo ativo para backup e recuperação (hot standby caso o Data Center 1 esteja inacessível).
- IDrive® e2 Data Center 3 como um armazenamento de dados imutável (para proteger dados contra erros administrativos, exclusões acidentais e ransomware). Um objeto de dados imutável não pode ser excluído ou modificado por ninguém, incluindo o IDrive® e2.